
深度学习笔记1——神经网络的搭建与简单应用
推荐阅读
前言
在写这篇文章时,对于神经网络的理解还不够,并没有说明神经网络到底是什么,并且推导神经网络后向传播的过程。这篇文章个人觉得是失败的,但同时也有一定价值。
此文章说明了神经网络的环境搭建tensorflow以及配置其能够GPU加速的过程,同时利用tensorflow做了一个简单的案例,为后续神经网络的学习解决了杂碎的问题。
本来我不打算发出来,但是考虑到不管是pytorch还是tensorflow,搭建能够调用gpu环境的过程都是很容易出错的,于是还是决定发出来。因为当时我自己搭建这个环境因为各种版本问题还有其他奇怪的问题,加上现有的大部分教程由于版本迭代问题已经不适合,浪费了起码半天的时间。
神经网络与深度学习
神经网络诞生于一个尝试创建能够模拟大脑的软件的动机。对于神经网络的研究始于20世纪50年代。中途被冷落了两次。在2005年,神经网络东山再起,其中的一些算法被深度学习重新命名,实际上深度学习和神经网路阐释着非常相似的事情。网络上有不少区别深度学习和神经网络的文章,但就当下的环境来说,深度学习其实就是神经网络,深度学习不过是业界为神经网络取的一种营销名字。
使用Tensorflow搭建神经网络
常用的人工神经网络搭建框架有Tensorflow和Pytorch等,这里使用tensorflow进行搭建。
环境搭建和导包遇到的问题:
问题1:
最开始是用Acaconda把tensorflow和Keras都安装了,然后导入时报错:
1 | AssertionError: Duplicate registrations for type 'optimizer' |
然后尝试卸载Keras,问题解决。而且卸载后conda list还找到了一个Keras,说明刚才可能多装了一个。
问题2:
1 | from tensorflow.keras import xxx |
报错:
1 | ModuleNotFoundError: No module named 'tensorflow.keras' |
最开始以为是Keras和tensorflow版本不搭配问题(当时还没分清Keras和tensorflow.keras是两个东西),检查了版本后无误,最终在这篇文章中找到了答案:keras学习- No module named ' tensorflow.keras ' 报错,看清 tf.keras与keras_Eric_Blog_csdn的博客-CSDN博客
原因是安装路径中间多了个python,所以导入应该这样写:
1 | from tensorflow.python.keras.layers import xxx |
tensorflow:GPU相关文件打开不了
各种报错:
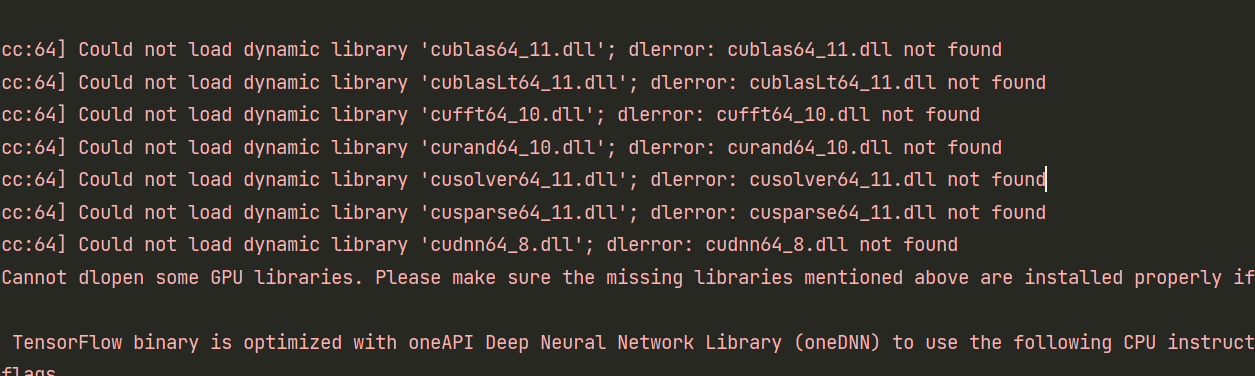
大概是说找不到调用GPU的这些文件,如果不解决它,就无法做到向量化,不能向量化那训练速度就会极慢,所以不能放着不管。 首先你得安装适合版本的Cuda toolkit,然后安装cuDNN,再安装tensorflow-gpu。参考:安装tensorflow的GPU版本(详细图文教程).
难崩。搞了半天,终于把这个问题解决了。这个环境真的搞得我绝望,各个版本试了又试,强烈建议按照上面贴的这个教程来!!!
最后选择的版本搭配:CUDA 11.6.0+cuDNN 8.4.0+tensorflow-gpu 2.9.1。如果你用的pycharm,一定一定要把环境换成conda!!!这是我血与泪的教训。
终于:
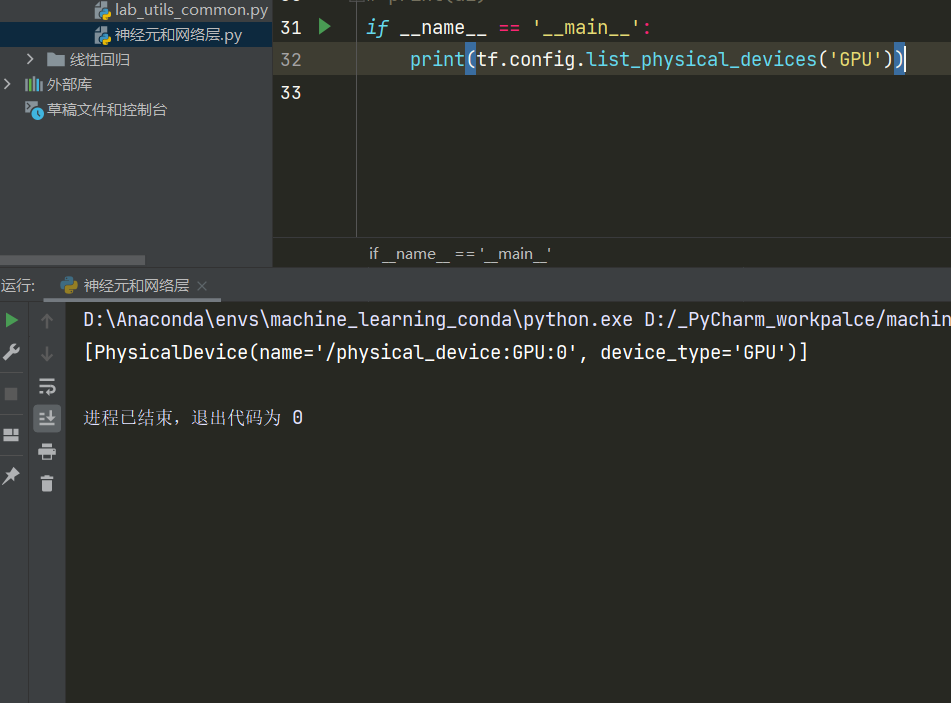
搭建一个简单的神经网络
问题引入:
现在有一批经过烘烤的咖啡豆,以及它们的烘烤温度和烘烤时间,现在我们知道哪些咖啡豆是好的(Good Roast)和坏的(Bad Roast),请根据已有数据构建一个神经网络,推测在什么温度范围内和烘烤时间范围内咖啡豆是好的。
数据绘图:

注:中间的线不用管它。
导入需要的包:
这里只给出神经网络相关包,并不是接下来用到的所有包。
1 | import tensorflow as tf |
Keras是一个高级的Python神经网络框架,已经被添加到TensorFlow 中,成为其默认的框架,为TensorFlow 提供更高级的API。
这里除了这种导包方式还有另一种方式:
1 | import tensorflow as tf |
但是注意你不能同时导入keras和tensorflow内置的keras,不然因为混用报错。我用的tensorflow 2.9.0,用第二种方法还是会报错,所以改为了第一种,暂时不清除是不是版本问题。
数据规范化
与之前学过的相同,对数据进行规范化可以加快反向传播的速度(暂时不用管反向传播是什么):
1 | X,Y = load_coffee_data() |
X:(200,2)矩阵,200个样例,2个特征(温度和烘烤时间);
Y:长200的列表,值为0或1,1代表Good Roast
复制数据,增加训练集的数量并减少训练代数?(不太懂,可能就是要增加训练集个数吧)
1 | Xt = np.tile(Xn,(1000,1)) |
构建神经网络模型
我们打算构建的神经网络模型长这样:
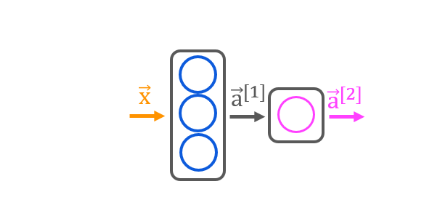
这个模型的激活函数都是sigmoid函数。可以看出,它一共有两层,第一层(layer 1)一共有三个神经元,第二层(layer 2)有一个神经元。像这样的layer又叫做密集层(Dense)。
现在考虑一个样例:输入值 \(\vec x = (x_1,x_2)\),因为layer 1有三个神经元,每个神经元能算出一个值,所以\(\vec x\)进入layer 1可以算出一个向量\(\vec a^{[1]} = (a_1^{[1]},a_2^{[1]},a_3^{[1]})\) ,上[ ]表示所在层数。然后\(\vec a^{[1]}\)进入layer 2,同理,可算出\(\vec a^{[2]} = (a_1^{[2]})\)。当\(a_1^{[2]}>=0.5\) 时,我们认为它是好的。
1 | tf.random.set_seed(1234) # applied to achieve consistent results |
设置随机数可以使每次训结果一样,便于对照。构建模型也可以写成这样:
1 | model = Sequential( |
tf.keras.Input(shape=(2,)这一句可以去掉。加上这一句可以为让模型塑形。下面是查看模型参数:
1 | model.summary() |
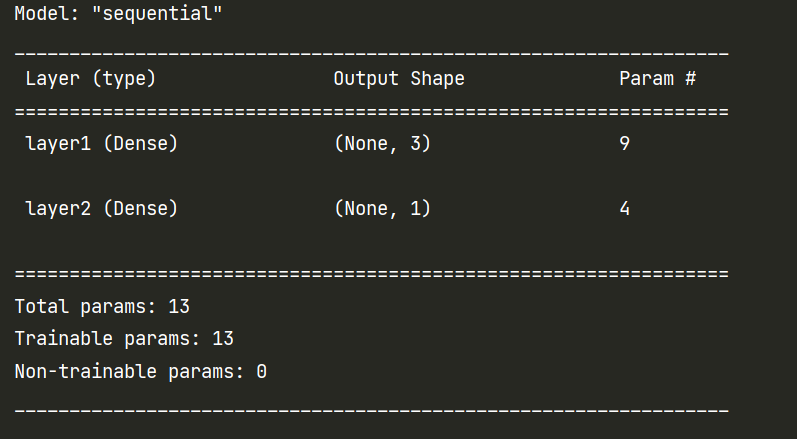
检查模型各层的参数是否正确:
权重W应为(输入的特征数,层中单元数),偏差b应为层数单元数。
1 | W1, b1 = model.get_layer("layer1").get_weights() |
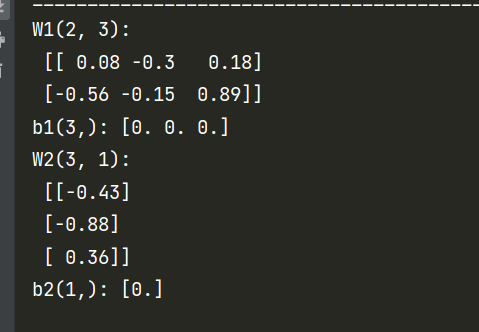
对应的值是模拟的初始值,随机数种子不同时会发现这些值会变化。我们这里注意它们的shape就行。
训练模型
下面的语句将在之后的文章详细介绍:
model.compile:定义损失函数和指定编译优化。
model.fit:运行梯度下降并训练模型。
1 | model.compile( |
在训练结束后,各权值就会更新成训练好的权值了:
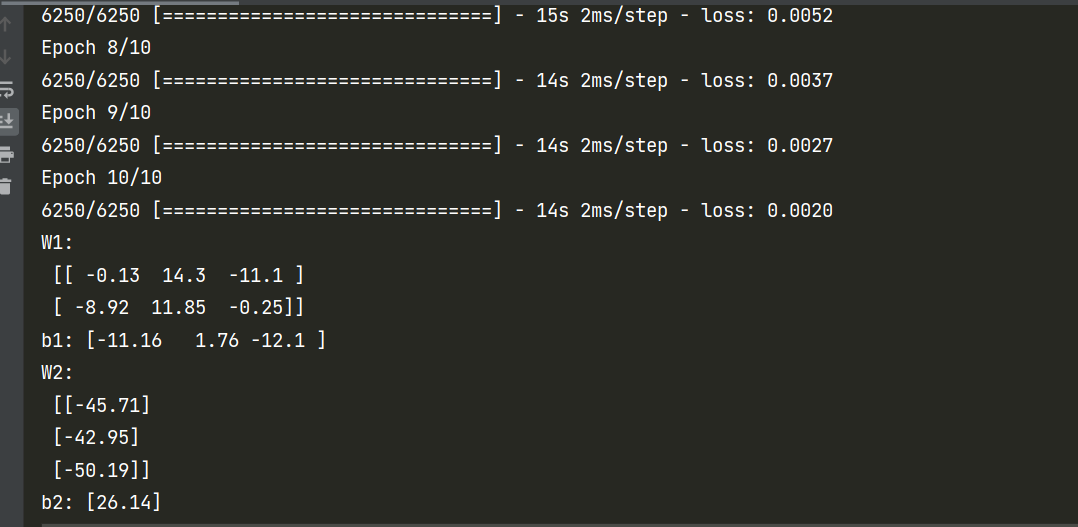
关于model.fit里的epochs参数:指训练集应该在训练期间被应用多少次,这里指定的10次。为了提高训练效率,训练集被分成了n个批次,一个批次大小为32,我们有200000个数据,所以被分成了6250批次。
补充:训练一般比较慢,为了不每次改代码都重新训练一次,我们可以将以前的训练的结果手动赋给各层:
1 | W1 = np.array([ |
模型预测
预测,并将概率转化为决策:
1 | X_test = np.array([ |
