机器学习笔记2——多元线性回归
推荐阅读
前言
多元线性回归总体思路和一元线性回归相同,都是代价函数+梯度下降,所以中心思想参考一元线性回归。
在回归分析中,如果有两个或两个以上的自变量,就称为多元回归。事实上,一种现象常常是与多个因素相联系的,由多个自变量的最优组合共同来预测或估计因变量,比只用一个自变量进行预测或估计更有效,更符合实际。
在开始之前,你可能需要先了解以下知识:
前置知识
向量化
当我们想自己实现向量的点乘时,通常会想到利用for循环来完成,例如有\(\vec{a}\cdot\vec{b}\),可以写为:
1 | x=0 |
然而,Python的Numpy库提供了一个dot()函数可以帮助我们进行向量化计算,作用是加快向量的运算速度,在数据量较大时效率会明显提高。其原理是Numpy利用了计算机底层硬件单指令多数据(SIMD)管道,这在数据集非常大的机器学习中至关重要。所以,向量化是机器学习中一个非常重要和实用的方法。
下图是使用Numpy的dot函数与自己利用for循环实现的向量点乘分别对长度各为10000000的向量a、b点乘运行时间比较:

特征缩放
为什么要特征缩放
当有多个特征时,在有的算法中,我们需要使这些特征具有相似的尺度(无量纲化)。
这里介绍特征缩放在多元线性回归中的作用。
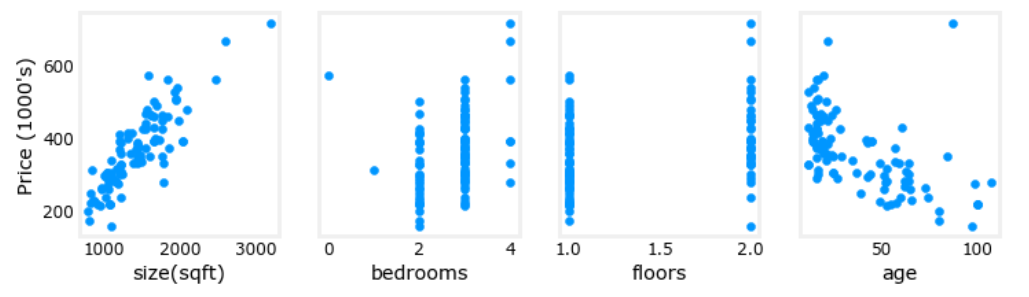
拿下面”问题引入“里得数据来说,各个特征的范围差距太大,我们将每个特征对价格的影响可视化,可以看出哪些因素对价格影响更大。会得到以下图像:
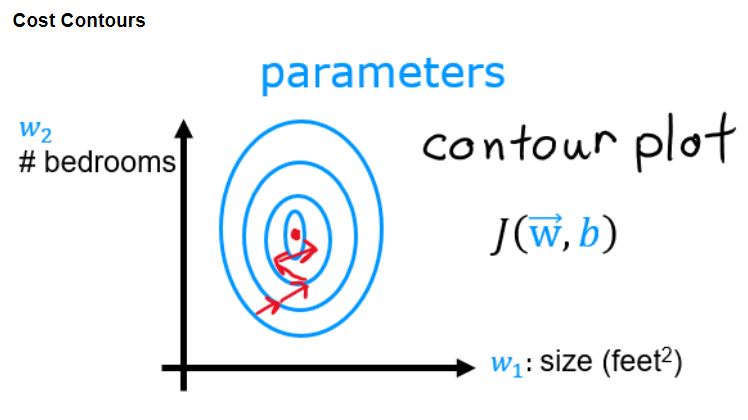
由于各个特征的数量差距过大,代价函数的等高线将会是扁长的,在梯度下降时也会是曲折的,而且计算时长相对会很长(因为学习率是通用的,为了照顾尺度大的特征,学习率必须设置的很小,学习率越小,下降速度就越慢):
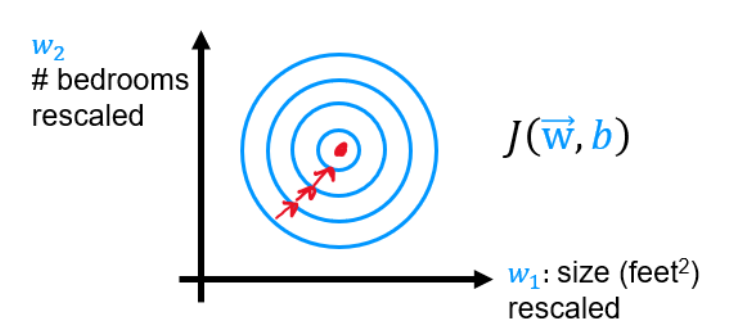
特征缩放将每个特征的范围统一,可以使梯度下降变”平滑“,并且大大提高计算速度(因为可以调大学习率)。
特征缩放的方法
特征缩放的方法有许多种,这里介绍两种:
均值归一化
公式:\(x_i = \frac{x_i - \mu}{max-min}\)
其中,\(\mu\)为样本中该特征的均值
1 | # 均值归一化 |
Z-score标准化(推荐)
公式:\(x_j^{(i)} = \frac{x_j^{(i)}-\mu_j}{\delta_j}\)
其中,\(j\)为\(X\)矩阵中的特征(或列),\((i)\)为样本序号。\(u_j\)为特征\(j\)的均值,\(\delta_j\)为特征\(j\)的标准差。
\(\mu_j = \frac{1}{m}\sum_{i=0}^{m-1}x_j^{(i)}\)
\(\delta_j^2 = \frac{1}{m}\sum_{i=0}^{m-1}(x_j^{(i)}-\mu_j)^2\)
1 | # Z-score标准化 |
或者使用sklearn:
1 | from sklearn import preprocessing |
问题引入
示例:现在你有以下数据,请利用这些值构建一个线性回归模型,并预测一栋1200平米,3间卧室,1层,年龄为40年的房屋的价格。
| 面积(平方) | 卧室数量 | 楼层数 | 房屋年龄 | 价格(1000s dollars) |
|---|---|---|---|---|
| 952 | 2 | 1 | 65 | 271.5 |
| 1244 | 3 | 2 | 64 | 300 |
| 1947 | 3 | 2 | 17 | 509.8 |
| .... | .... | .... | .... | .... |
多元线性回归模型
多元线性回归函数
对于上面提到的数据,一共有四种特征(面积,卧室数量,楼层,房屋面积),记为\(x_1,x_2,x_3,x_4\),每个特征分别需要一个\(w\),所以对应的线性回归函数为\(f(x) = w_1x_1+w_2x_2+w_3x_3+w_4x_4+b\).
推广到一般多元线性回归函数,即:
\(f(x) = w_1x_1+...+w_nx_n+b\) , 其中,n为特征数量。
观察\(f(x)\),我们发现可以将\(w\)看作一列,\(x\)看作一列。于是\(f(x)\)又可以写为:\(f_{\vec{w},b}(\vec{x}) = \vec{w}\cdot\vec{x}+b\), (注意为点乘)
这样我们的目标便是利用已知数据通过梯度下降算法找到最合适的\(\vec{w}\)和b。
转化为矩阵
我们可以将训练集转化为\((m,n)\)的矩阵,m表示示例,n表示特征,于是训练集X可以写为:
\[ \begin{pmatrix} x_{0}^{(0)}&x_{1}^{(0)}&...& x_{n-1}^{(0)} \\ x_{0}^{(1)}&x_{1}^{(1)}&...& x_{n-1}^{(1)} \\...\\x_{0}^{(m-1)}&x_{1}^{(m-1)}&...& x_{n-1}^{(m-1)}\end{pmatrix} \quad \] 注:\(\vec{x}^{(i)}\)表示含有第i个示例的向量,\(x_j^{(i)}\)表示第i个示例的第j个特征。因为每种特征对应一个\(w_i\),所以有向量:
\[ \vec{w} = \begin{pmatrix}w_0\\w_1\\...\\w_{n-1}\end{pmatrix} \quad \]
多元线性回归模型的代价函数
因为\(\hat{y}^{(i)} = f_{\vec{w},b}(\vec{x}^{(i)})=\vec{w}\cdot\vec{x}^{(i)}+b\), 其中\(\hat{y}^{(i)}\)为将第i个示例的向量带入回归函数得出的预测值。那么根据一元线性回归的代价函数的定义,可得多元线性回归模型的代价函数为:
\(J(\vec{w},b) = \frac{1}{2m}\sum_{i=0}^{m-1}(\hat{y}^{(i)}-y^{(i)})^2= \frac{1}{2m}\sum_{i=0}^{m-1}(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2\)
多元线性回归模型梯度下降函数
重复同时进行下列行为直到收敛:
\(w_j = w_j - a\frac{\partial J(\vec w,b)}{\partial w_j},\quad j = 0,1,...,n-1\)
\(b = b - a\frac{\partial J(\vec w,b)}{\partial b}\)
其中,a为学习率。化简偏导得:
\(\frac{\partial J(\vec w,b)}{\partial w_j} = \frac{1}{m}\sum_{i=0}^{m-1}(f_{\vec w,b}(\vec x^{(i)})-y^{(i)})x_j^{(i)}\)
\(\frac{\partial J(\vec w,b)}{\partial b} = \frac{1}{m}\sum_{i=0}^{m-1}(f_{\vec w,b}(\vec x^{(i)})-y^{(i)})\)
其中,n是特征数量,m是训练集示例数量。
收敛时的\(\vec w,b\)即为所求。
问题解析(含代码)
导入并标准化训练集
数据就不上传了,如果想动手测验,直接搞个矩阵把上面那三行当成训练集就行。
注意标准化时需要把均值和标准差也返回过去,便于对测试数据进行缩放。
1 | import copy |
多元线性代价函数
这里只是把代码写出来,实际上计算回归函数时用不上。
对应公式:\(J(\vec{w},b) = \frac{1}{2m}\sum_{i=0}^{m-1}(\hat{y}^{(i)}-y^{(i)})^2= \frac{1}{2m}\sum_{i=0}^{m-1}(f_{\vec{w},b}(\vec{x}^{(i)})-y^{(i)})^2\)
1 | # 代价函数 |
梯度计算函数
对应公式:
\(\frac{\partial J(\vec w,b)}{\partial w_j} = \frac{1}{m}\sum_{i=0}^{m-1}(f_{\vec w,b}(\vec x^{(i)})-y^{(i)})x_j^{(i)}\)
\(\frac{\partial J(\vec w,b)}{\partial b} = \frac{1}{m}\sum_{i=0}^{m-1}(f_{\vec w,b}(\vec x^{(i)})-y^{(i)})\)
1 | # 计算梯度 |
梯度迭代函数
对应公式:
重复同时进行下列行为直到收敛。
\(w_j = w_j - a\frac{\partial J(\vec w,b)}{\partial w_j},\quad j = 0,1,...,n-1\)
\(b = b - a\frac{\partial J(\vec w,b)}{\partial b}\)
1 | # 梯度下降 |
设置学习率,计算回归函数和预测
预测时必须先使用之前计算出的均值和标准差把测试数据缩放再进行预测!
1 | if __name__ == '__main__': |
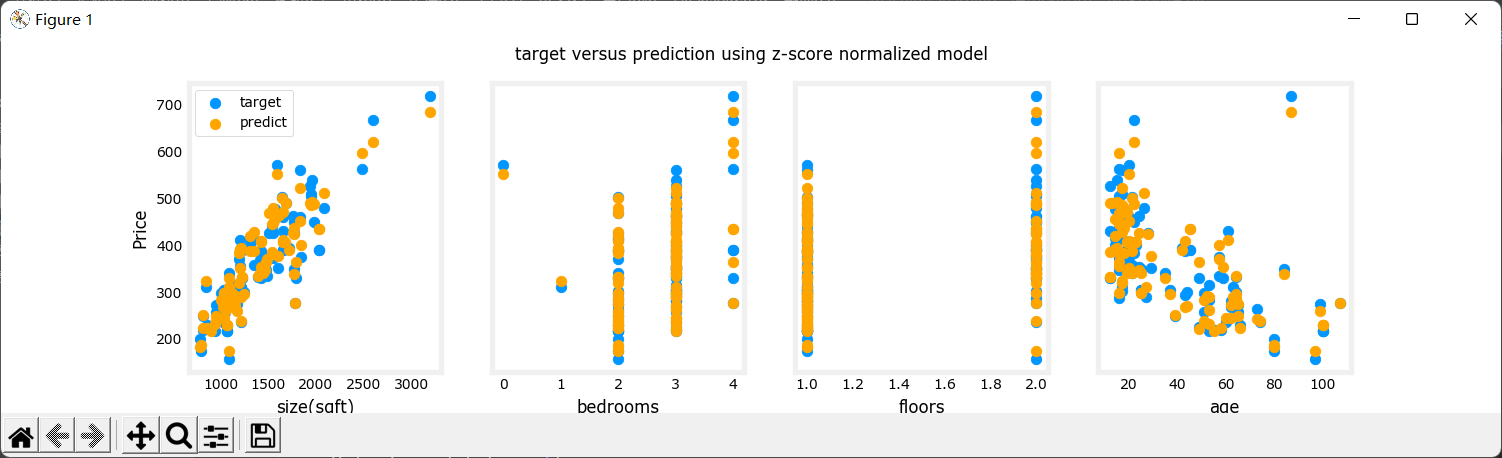
结果:
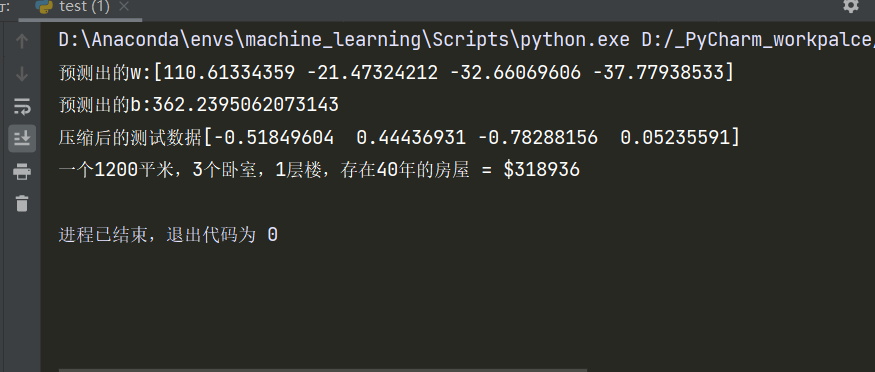
就当那个世界的房子都这么便宜吧。
关于线性回归模型的评估:
常用的有均方误差和均方根误差等方法,这里留个空以后出篇文章,暂时放一放。
补充:学习率a的评估
一般可以通过两个方面来评估:
1.每次计算出的梯度,如果学习率合适,那么这个值应该在不断下降。
2.梯度下降在整个代价函数上的”跳跃“变化,如果学习率合适,它应该是不断往下跳的。
学习率过大:如果学习率过大,每次计算出的梯度会发生类似下面左图的情况。右图是学习率过大的情况下每次梯度下降在总成本函数上的变化,注意它是从下往上跳的,最后会导致结果发散。

学习率过小:它虽然可以收敛,但是过程比较慢。
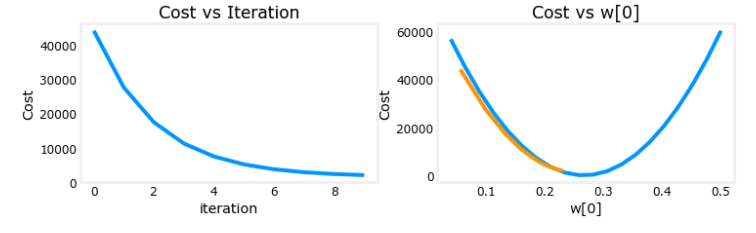
学习率合适:

补充:浅谈正规方程
求解线性回归不止有梯度下降一种方法,其实还有另一种方法求解,即正规方程。不过在这里不讨论它的详细公式,只拿它与梯度下降做一个对比。
| 梯度下降 | 正规方程 |
|---|---|
| 需要选择学习率 | 不需要选择学习率 |
| 需要多次迭代 | 一次计算得出 |
| 当特征数量较多时也能较好使用 | 时间复杂度为\(O(n^3)\),当特征数量较多时太慢 |
| 也适用于除线性回归的其他模型 | 只适用于线性回归模型 |
补充:利用sklearn完成线性回归预测
关于StandardScaler()函数:sklearn中StandardScaler()
关于SGDRegressor:随机梯度线性回归,随机梯度下降是不将所有样本都进行计算后再更新参数,而是选取一个样本,计算后就更新参数。
关于LinearRegression:也是线性回归模型,这里没用,可以自己查。
绘图模块的代码可能要自己改改。其余详细说明见代码:
1 | import numpy as np |
结果:

训练集预测值与真实值结果对比