
【NLP】多标签分类【上】
简介
《【NLP】多标签分类》主要介绍利用三种机器学习方法和一种序列生成方法来解决多标签分类问题(包含实验与对应代码)。共分为上下两篇,上篇聚焦三种机器学习方法,分别是:Binary Relevance (BR)、Classifier Chains (CC)、Label Powerset (LP),下篇聚焦利用序列生成解决多标签分类方法,将使用Transformer完成该任务。
本文共分为5节,第一节介绍实验数据来源、任务说明;第二节介绍BR、CC、LP各自原理以及优缺点;第三节介绍本文使用的多标签分类评估标准;第四节介绍实验环境、实验步骤、实验评估以及相关代码;第五节为全文总结。
个人博客与相关链接
本文相关代码和数据集已同步上传github: issey_Kaggle/MultiLabelClassification at main · iceissey/issey_Kaggle (github.com)
本文代码(Notebook)已公布至kaggle: XLNET embedding and machine learning(BR、CC、LP) | Kaggle
博主个人博客链接:issey的博客 - 愿无岁月可回首
实验数据与任务说明
数据来源:Multi-Label Classification Dataset (kaggle.com)
任务说明:
- 背景:NLP——多标签分类数据集。
- 内容:该数据集包含6个不同的标签(计算机科学、物理学、数学、统计学、定量生物学、定量金融),用于根据摘要和标题对研究论文进行分类。 标签列中的值1表示该标签属于该论文,每篇论文可以有多个标签为1。
多标签分类任务与相关算法
多标签分类任务简介
多标签分类(Multi-label Classification)是一种机器学习任务,其中每个输入样本可以分配给多个类别标签,而不是只能分配给一个单一的类别标签。与传统的单标签分类不同,多标签分类允许一个样本同时属于多个类别,这更符合现实世界中许多复杂问题的性质。
相关算法
多标签分类方法主要分为两大类,分别是问题转换方法和算法适应方法,本篇主要集中于问题转换方法中的前三种。
问题转换方法:这些方法通过转换问题使其适用于标准的单标签分类算法。主要包括以下几种:
- 二元相关性(Binary Relevance,
BR):这种方法将多标签问题分解成多个独立的二分类问题,每个标签都被视为一个独立的二分类问题。
- 优点:
- 简单易实现:BR方法的实现相对简单直接,因为它将复杂的多标签问题分解为多个标准的二分类问题。
- 灵活性:由于BR方法在每个标签上独立训练分类器,因此可以针对不同的标签选择最适合的分类算法。
- 可扩展性:在新标签加入时,只需增加相应的二分类器,而无需修改或重新训练其他分类器。
- 高效:由于每个标签都独立处理,可以并行训练和预测,提高了处理速度。
- 缺点:
- 忽略标签依赖性:BR方法的主要缺点是它忽略了标签之间的相关性。在实际应用中,标签往往不是完全独立的,它们之间的关联可能对分类结果有重要影响。
- 预测性能问题:由于不考虑标签间的依赖关系,BR方法在某些复杂的多标签问题上的预测性能可能不如那些能够考虑标签依赖性的方法。
- 优点:
- 标签幂集(Label Powerset,
LP):在这种方法中,每一种标签组合都被视为一个独立的类别,从而将多标签问题转换为单标签多类别问题。
- 优点
- 考虑标签之间的依赖性:LP方法能够捕捉和利用标签之间的相关性。这在标签彼此之间存在强烈依赖性的情况下特别有用。
- 简化模型训练:与需要为每个标签单独训练一个分类器的二元相关方法相比,LP只需训练一个模型,这可以简化训练过程。
- 直接预测标签集合:LP方法直接预测整个标签集合,避免了将标签预测作为独立事件处理时可能出现的问题。
- 缺点:
- 组合爆炸:当标签数量增多时,可能的标签组合数会指数级增长,导致计算和存储需求急剧增加。由于组合爆炸的问题,标签幂集无法处理标签种类较多的问题。
- 数据稀疏问题:对于一些罕见的标签组合,可能没有足够的训练数据,这会导致模型性能下降。
- 效率问题:尽管只需训练一个模型,但模型可能变得非常复杂,特别是当存在大量的标签组合时。
- 优点
- 分类器链(Classifier Chains,
CC):这种方法通过构建一个分类器链来解决标签之间的依赖问题。每个分类器在链中负责一个标签,并将前面分类器的预测结果作为额外的输入。
- 优点:
- 考虑标签间的依赖性:分类器链通过序列化的方式考虑标签间的依赖关系,这在标签相关性显著的情况下特别有用。
- 可扩展性:相比于标签幂集方法,分类器链在处理大量标签时更为高效,因为它避免了组合爆炸问题。
- 较好的泛化能力:相对于二元相关方法,分类器链通常能够提供更好的泛化能力,尤其是在标签之间存在依赖关系时。
- 缺点:
- 链的顺序敏感性:分类器链的性能可能受到链中分类器顺序的影响。不同的标签顺序可能导致不同的性能表现。
- 错误传播:链中早期分类器的错误可能会传播到链的后面部分,影响整体性能。
- 优点:
- 随机k标签子集(Random k-Labelsets,
RAkEL):这种方法是通过随机选择标签子集并对每个子集应用LP方法,然后综合这些模型的预测结果。
由于本文涉及的实验总共标签总类也才6种,所以没有使用这种方法而直接选择了LP。- 优点:
- 缓解组合爆炸问题:通过在较小的标签子集上应用LP方法,RAkEL减少了可能的标签组合数量,从而缓解了标签幂集法中的组合爆炸问题。
- 考虑标签间的依赖性:与二元相关方法相比,RAkEL能够捕捉标签子集内部的依赖关系,提高了模型的准确性。
- 更好的泛化能力:由于模型在多个随机选择的标签子集上训练,这可以增加模型的泛化能力。
- 缺点:
- 随机性:标签子集的随机选择可能导致模型性能的不稳定性。
- 可能忽略某些标签关系:如果某些相关标签从不在同一个子集中出现,那么它们之间的关系可能不会被模型捕捉到。
- 计算复杂度:虽然RAkEL缓解了组合爆炸问题,但仍需要训练多个LP模型,这可能比单一的分类器链或二元相关方法更耗时。
- 预测一致性问题:不同的标签子集模型可能对相同的标签做出不同的预测,需要有效的机制来整合这些预测。
- 参数选择:选择合适的子集大小(k值)和子集数量是RAkEL方法的关键,这可能需要根据具体的数据集进行调整。
- 优点:
算法适应方法:这些方法通过修改现有的学习算法使其能够直接处理多标签数据。主要包括以下几种:适应决策树(Adapted Decision Trees)、适应神经网络(Adapted Neural Networks)、适应支持向量机(Adapted Support Vector Machines)、k最近邻修改版(k-Nearest Neighbors Adaptation)。
除问题转换方法和算法适应方法外,深度学习方法也在多标签分类中表现出色。在本文的下篇中,会介绍将多标签分类转换为多标签序列生成任务的方法。
多标签分类评估方法
1. 准确率(Accuracy)
- 定义:准确率是正确预测的样本数与总样本数的比例。在多标签分类中,如果所有的标签都被准确预测,则一个样本的预测被认为是正确的。
- 实现:使用sklearn.metrics的accuracy_score方法实现。
- 备注:由于只有当某样本所有标签全预测正确,才能算该样本预测正确,导致这种方式计算出的Acc结果普遍偏低。在下篇中,会介绍另一种计算Acc的方式,即先计算每一个label的Acc,然后在取平均值。
2. 精确度(Precision)- 微观平均(Micro-average)
- 定义:精确度是模型正确预测为正的实例(真正例)占模型预测为正的所有实例(真正例和假正例)的比例。
- 计算方法:微观平均精确度是通过汇总所有类别的真正例和假正例的数量,然后计算总体精确度得到的。在多标签设置中,这意味着考虑所有标签的预测结果,而不是单独考虑每个标签。
- 实现:使用sklearn.metrics的precision_score方法实现。
3. 召回率(Recall)- 微观平均(Micro-average)
- 定义:召回率是模型正确预测为正的实例占实际为正的所有实例(真正例和假负例)的比例。
- 计算方法:微观平均召回率是通过汇总所有类别的真正例和假负例的数量,然后计算总体召回率得到的。它反映了模型在所有标签上的总体能力,来正确地识别正类实例。
- 实现:使用sklearn.metrics的recall_score方法实现。
4. F1 分数(F1 Score)- 微观平均(Micro-average)
- 定义:F1 分数是精确度和召回率的调和平均值,用于平衡这两个指标。
- 计算方法:微观平均 F1 分数是基于微观平均精确度和召回率计算得到的。它是这两个指标的调和平均值,因此在精确度和召回率都重要时,提供了一个综合性能度量。
- 实现:使用sklearn.metrics的f1_score方法实现。
实验
实验环境
本实验是在以下配置的环境中进行的:
- 编程语言和版本:
- Python 3.9:一个广泛使用的高级编程语言,适用于数据科学和机器学习项目。
- 主要库和框架:
- NumPy 1.23.3:用于高性能科学计算和数据分析的基础包。
- Pandas 1.4.4:提供高效的数据结构和数据分析工具。
- Matplotlib 3.5.3:用于数据可视化的绘图库。
- PyTorch 1.13.0:一个灵活的深度学习框架,适用于研究和生产。
- PyTorch CUDA 11.6:用于在NVIDIA GPU上加速PyTorch运算的CUDA支持库。
- 机器学习和深度学习库:
- Transformers 4.18.0:由Hugging Face提供的,用于自然语言处理的预训练模型和转换器。
- scikit-learn 1.2.2:提供简单有效的数据挖掘和数据分析工具。
- scikit-multilearn 0.2.0:用于多标签分类的机器学习库。
实验步骤
本篇的实验步骤主要包括:1)数据观察与预处理阶段。2)词嵌入阶段。3)模型训练与测试阶段。4)进一步探索。
数据观察与预处理
数据观察
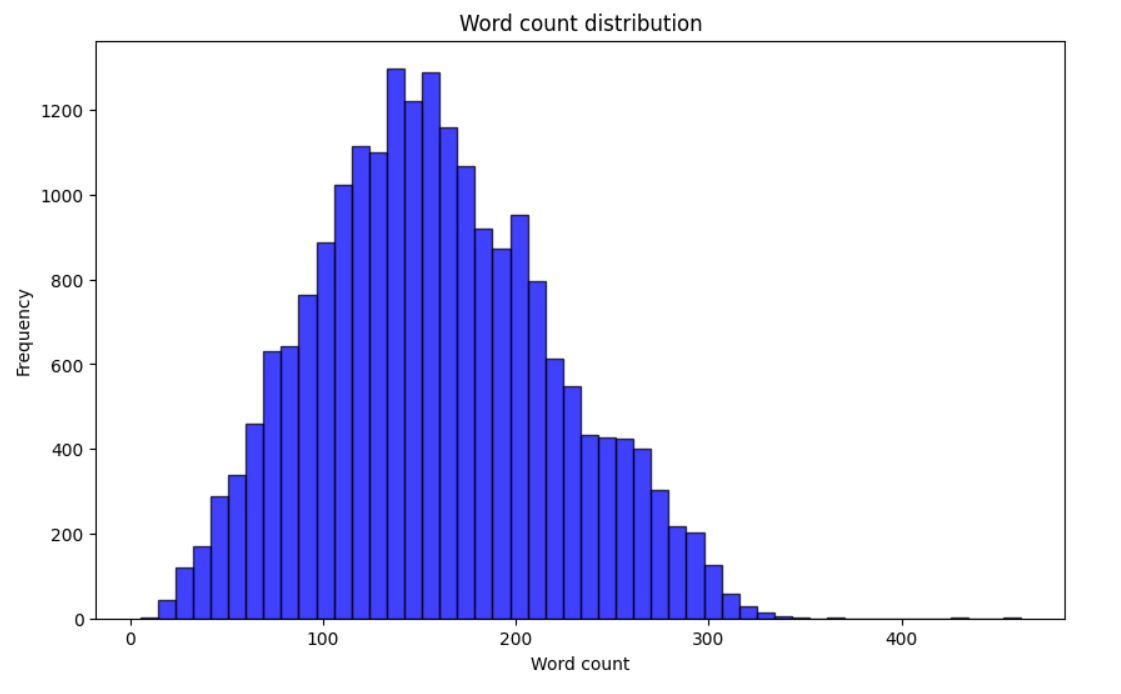
- 单词数量统计:在本实验中,我们专注于观察数据集中每个文本项的单词数量。通过统计信息,我们可以了解数据集中文本的长度分布。
数据预处理
- 最小化预处理:由于本实验在后续词嵌入时使用XL-NET模型,且与使用传统文本分类方法相比,使用XL-NET等先进的预训练模型时,常规的文本预处理步骤(如去除特殊符号、停用词移除、词形还原)并不是必要的。这些模型的分词器能够有效处理原始文本中的复杂词汇结构,同时保留对上下文理解至关重要的词汇和语法特征。
- 实验步骤完整性:虽然在本实验中不需要传统的预处理步骤,但为了保持实验步骤的完整性和系统性,我们仍然包含了这一部分。这有助于清晰地展示实验流程,并为可能需要适当预处理的后续研究提供参考。
代码部分
- 准备工作
导入相关库
1 | import numpy as np |
检查GPU是否可用。在上篇的实验中,如果GPU不可用问题也不大,直接用CPU跑即可,因为上篇使用GPU的地方只有embedding。不过在下篇时GPU是必要的,如果本地环境不支持,建议放到云服务器(如kaggle)上跑。
1 | # Set the device to GPU (if available). |
1 | Using device: cuda |
- 准备数据集
由于题目要求使用TITLE和ABSTRACT共同参与预测,所以简单做一下拼接。
1 | """Prepare the data""" |
1 | 20972 |
- 统计combined_text单词分布
检查combined_text最长、最小、平均单词长度。
1 | """View the distribution of word counts""" |
1 | Word count statistics: |
绘制单词分布柱状图。
1 | plt.figure(figsize=(10, 6)) |
词嵌入阶段
XL-NET嵌入
在本实验中,我们使用了预训练的XL-NET模型来生成文本嵌入,这是一个关键步骤,旨在将文本转换为能被机器学习模型有效处理的数值形式。
- 模型和分词器加载:我们首先加载了XLNet的基础模型(
xlnet-base-cased)和对应的分词器。这个分词器将负责将原始文本转换成模型可以理解的令牌序列。 - 设定批处理大小:考虑到计算效率和内存限制,我们设定了一个合适的批处理大小(
batch_size = 32)。这意味着每次向模型输入32个文本样本进行处理。
嵌入生成过程
- 文本准备和处理:我们将数据集中的文本转换为字符串列表,并按批次处理。每个批次的文本被分词器编码,其中包括截断和填充操作以确保文本长度一致。
- 嵌入计算:对于每个批次,我们将编码后的文本输入XL-NET模型。通过模型,我们获取每个文本的嵌入表示,这些表示捕捉了文本中的语义信息。
- 处理和存储嵌入:得到的嵌入被转换为NumPy数组,并被收集在一起。最终,所有的嵌入被存储在HDF5文件格式中,方便后续的机器学习任务使用。
不进行微调的决定
- 一次性嵌入过程:本实验选择不对XL-NET模型进行微调,而是直接使用预训练模型一次性生成所有文本的嵌入。这种方法简化了实验流程,同时允许我们充分利用XL-NET预训练模型的强大语义捕捉能力。
- 效率和实用性:将所有文本的嵌入预先计算并存储起来,提高了后续实验步骤的效率。
代码部分
- 加载分词器和预训练模型
1 | """Load the XLNet tokenizer and model""" |
- embedding,并将嵌入好的向量一次性存储下来
tqdm是一个可视化进度条的库,可以方便的查看处理进度。
这里解释一下如何从XL-NET模型的输出中提取嵌入(embedding)。
- 模型输出理解:当我们将输入文本通过XL-NET模型处理时,
outputs对象包含了多个不同的输出组件。其中,last_hidden_state是一个多维张量,其维度通常是[批处理大小, 序列长度, 隐藏单元数]。这个张量包含了模型对每个输入令牌的最后一层隐藏状态的表示。 - 选择特定令牌的嵌入:在XL-NET和类似的变压器模型中,每个输入令牌都有一个对应的输出向量。在这里,
outputs.last_hidden_state[:, 0, :]表示我们选择了每个序列的第一个令牌(通常是特殊的分类令牌,如BERT中的[CLS])的输出向量。这个向量被认为是整个输入序列的聚合表示,并经常用于分类任务。
还记得我在今年早些的时候做的那个Bert+Bilstm的任务【NLP实战】基于Bert和双向LSTM的情感分类【中篇】-CSDN博客,当时我在embeding后直接取的last_hidden_state,也就是个三维向量,接着用Bilstm得到最终的二维隐藏层(只保留了最后的隐藏状态),现在想来当时对Bert的理解还是不到位。然而这两种方法都是有效的,不过一个是词维度的嵌入,一个是句维度的嵌入,本文上篇使用的embedding就是句维度的嵌入。
1 | # Specify the directory path |
1 | 100%|██████████| 656/656 [15:11<00:00, 1.39s/it] |
可以看到,现在我们的数据集中的text(也就是'combined_text'),被编译为了一个768维度的向量。一共有20972行text,所以嵌入矩阵为(20972, 768)。
模型训练与测试阶段
数据准备
- 数据集加载与分割:我们从CSV文件中加载了数据集,并提取了标签列。接着,使用XL-NET生成的嵌入向量作为特征,将数据集分割为训练集和测试集,保证了模型训练和评估的有效性和公正性。
多标签分类方法
我们采用了三种不同的多标签分类方法:二元相关(Binary Relevance, BR)、分类器链(Classifier Chains, CC)和标签幂集(Label Powerset, LP)。每种方法都使用了随机森林分类器作为基学习器。
- 二元相关(Binary Relevance):这种方法将多标签问题分解为多个独立的二分类问题。我们首先训练了BR模型,并记录了训练时间。接着,我们在测试集上进行预测,并计算了准确度、精确度、召回率和F1分数(微观平均)。
- 分类器链(Classifier Chains):这种方法通过构建一个分类器链,使每个分类器在预测时考虑到之前分类器的输出。同样,我们训练了CC模型,记录了训练时间,并在测试集上进行了评估。
- 标签幂集(Label Powerset):LP方法将多标签问题转换为单标签多类别问题。我们训练了LP模型,并对其进行了测试集上的性能评估。
性能评估
评估指标:为了全面评估每种方法的性能,我们计算了准确度、精确度、召回率和F1分数(均采用微观平均),评估指标详细说明如第三节所示。这些指标帮助我们理解不同方法在处理多标签分类任务时的效果和局限。
训练时间和性能:每种方法的训练时间都被记录下来,以评估其在实际应用中的可行性。
代码部分
- 导入相关库
1 | from skmultilearn.problem_transform import BinaryRelevance, ClassifierChain, LabelPowerset |
- 准备数据
提取标签。
1 | data_path = "/kaggle/input/multilabel-classification-dataset/train.csv" |
1 | (20972, 6) |
加载经过XL-NET嵌入后的隐向量。
1 | # Load embedding vectors |
1 | (20972, 768) |
用于后续测试,如果要让模型快速运行就把注释打开。
1 | # TEST |
分割数据集。
1 | # Split the dataset into a training set and a test set. |
1 | (16777, 768) (4195, 768) (16777, 6) (4195, 6) |
- 模型训练与测试
1 | # Binary Relevance |
1 | =================================== |
结果分析
可以看到,LP不仅训练时间最短,而且Acc和F1都要更好。因此,我们可以继续探究使用支持向量机(SVM)作为基分类器的效果。
进一步探索--使用SVM的标签幂集方法
实验设计
- 基分类器更换:鉴于LP方法的成功,我们决定用SVM替换原先的随机森林分类器,以进一步探索不同基分类器对多标签分类任务性能的影响。
- SVM配置:我们选择了线性核的SVM,并将其包装在
OneVsRestClassifier中,以适应多类别问题。线性核是因其在处理高维数据时的有效性和计算效率而被选用。
训练和评估
模型训练:使用LP方法结合SVM分类器训练模型,并记录了训练时间。
性能评估:在测试集上评估了模型的准确度、精确度、召回率和F1分数(均采用微观平均)。这些指标有助于我们全面了解SVM在多标签分类任务中的表现。
训练时间对比:与之前使用随机森林的LP方法相比,我们特别关注SVM版本的训练时间,以评估其在实际应用中的效率。
代码部分
1 | from sklearn.svm import SVC |
1 | =================================== |
结果分析
可以看到,LP-SVM的训练时间比使用随机森林的LP长了184倍,但所有评估标准都比使用随机森林的LP好。显然,它是我们本篇中最好的模型。
总结
本篇为《【NLP】多标签分类》的上篇,本文详细细探讨了多标签分类问题,聚焦于三种机器学习方法(Binary Relevance, Classifier Chains, Label Powerset),展示了每种方法的原理、优缺点,以及具体的实验评估和代码实现。本文还探讨了如何使用XL-NET做嵌入。实验结果表明,标签幂集方法配合随机森林分类器在训练时间和性能(准确度和F1分数)上表现良好。进一步探索使用SVM作为基分类器后,虽然训练时间增长,但所有评估标准均有所提升,显示出更好的性能。文章通过详细的实验步骤和评估方法,为选择适合特定多标签分类任务的方法提供了实证依据。